
코워크로 스타트업 RAG구축하기

오늘은 조금 특별한 이야기를 해보려고 해요. 개발자가 아닌 기획자가 AI와 대화만으로 회사의 문서 153개를 정리하고, 누구나 검색할 수 있는 시스템을 만든 이야기입니다. 코드는 한 줄도 직접 쓰지 않았어요. 진짜로요.
2026년 1월, 앤트로픽이 클로드 코워크(Claude Cowork)를 출시했다는 뉴스를 봤습니다. 그 자체로는 "또 AI 나왔구나" 싶었는데, 뉴스 내용이 좀 달랐어요. SaaS 기업 주가가 도미노처럼 무너지고, S&P 소프트웨어 지수는 2008년 이후 최악의 1월을 기록했다는 겁니다. SAP가 하루 만에 16% 폭락하고, 소프트웨어 시가총액 435조 원이 증발했다는 뉴스까지.
"도대체 뭔데 이 정도야?"
궁금해서 찾아보니 핵심은 두 가지였습니다. 첫째, 기획자도 쓸 수 있다는 것. 코딩 없이 자연어로 파일을 다루는 AI 에이전트라는 점. 둘째, 내 로컬 파일에 직접 접근할 수 있다는 것. 수동 업로드 없이 AI가 내 컴퓨터 파일을 읽고 쓸 수 있다니. 이건 단순한 챗봇이 아니라 진짜 '동료'가 될 수 있겠다 싶었습니다.
고민 없이 가장 비싼 Max 20x 요금제를 질렀습니다. 월 200달러. 아깝긴 했지만, 이걸로 회사 문서 시스템을 바꿀 수 있다면 충분히 가치 있다고 판단했어요.
남는 맥북 한 대, RAG의 씨앗이 되다
회사에 놀고 있던 맥 노트북이 하나 있었습니다. 여기에 코워크를 별도로 설치했어요. 그리고 그동안 쌓인 모든 회사 문서를 옮겨 놓았습니다.
왜 제 개인 노트북이 아니라 별도 맥에 설치했냐고요? 이유는 간단합니다. 나 혼자 쓰려는 게 아니었거든요. RAG를 제대로 구축하면, 이 맥북이 회사의 '문서 두뇌'가 되어서 모든 직원이 "예전에 클라이언트한테 보냈던 제안서 어디 있지?"라고 물어보면 AI가 즉시 찾아주는 시스템을 만들고 싶었습니다.
사업계획서, 결과보고서, IR자료, 보도자료, 제안서... 스타트업을 5년 운영하면서 쌓인 문서가 어느새 몇 천여개를 훌쩍 넘었거든요. 정부 과제 신청서만 30개가 넘는데, 새 문서를 쓸 때마다 "예전에 비슷한 거 썼는데..."하면서 폴더를 뒤지는 게 일상이었습니다.
의욕 넘치게 문서를 몽땅 옮겨놓고 코워크에게 "이 문서들 읽어봐"라고 했습니다. 그런데 문제가 생겼어요.
한컴 한글(HWP) 파일을 제대로 읽지 못하는 겁니다.
정부 과제 서류의 대부분이 HWP인데, AI가 이걸 못 읽으면 절반 이상의 문서가 무용지물이에요. 그리고 설상가상으로, 고용량 문서를 넣으면 코워크가 한없이 느려지고 답답한 AI로 변신했습니다. 마치 10년 된 컴퓨터에서 엑셀 파일 열듯이요.
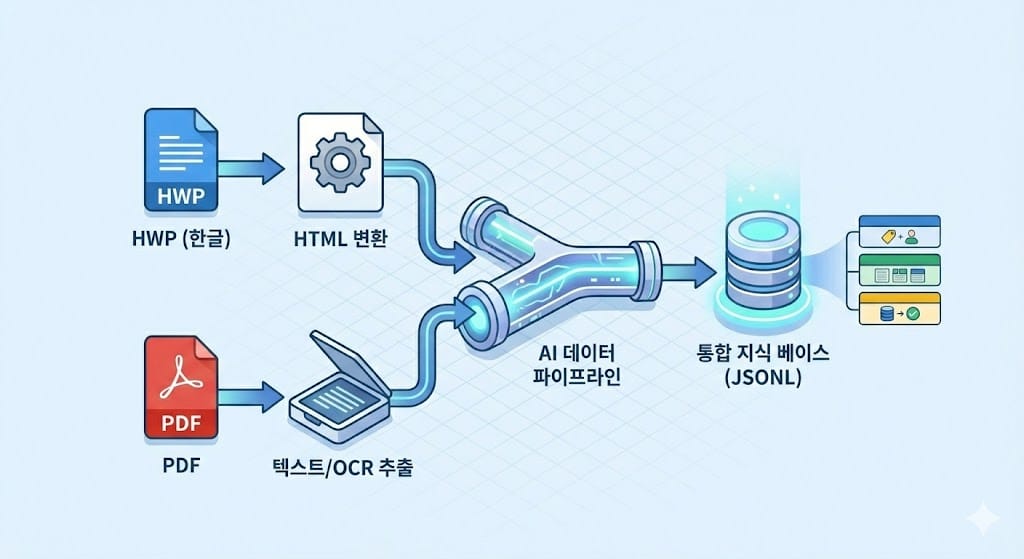
"이래서는 안 되겠다."
코워크와의 대화를 통해 잡은 전략은 이랬습니다. PDF 문서 (77개) — PyMuPDF로 텍스트를 추출하고, 텍스트가 없는 스캔 페이지는 OCR로 처리. 표 구조까지 살렸습니다. 한글 문서 (77개) — HWP를 직접 파싱하는 건 고통스러운 일이라, 한글 프로그램에서 HTML로 내보내기한 파일을 사용했습니다. 여기서 만만치 않았던 건 euc-kr 인코딩 문제, 이미지 경로 깨짐, 그리고 h1~h6 태그 없이 CSS 클래스로만 제목을 구분하는 HWP 특유의 HTML 구조였어요.
처음에는 단순하게 생각했어요. 문서를 잘라서 벡터 DB에 넣고, 질문하면 관련 조각을 찾아 답하면 되지 않을까?
하지만 저희가 원한 건 달랐습니다. 만약 프롬프트에 "교육기업고객 대상 4~5페이지짜리 회사소개서를 새로 만들어줘"라고 했을 때, AI가 알아야 하는 건:
- 이 회사가 어떤 제품을 몇 개 가지고 있는지 (사실 정보)
- 예전에 출판사 대상으로 쓴 문서들은 어떤 톤과 구조였는지 (문서 메타데이터)
- 각 문서의 어떤 섹션이 제품 소개에 해당하는지 (본문 검색)
단순한 텍스트 조각이 아니라, "어떤 종류의 문서인지", "누구를 대상으로 썼는지", "어떤 제품에 관한 것인지"까지 알아야 쓸만한 결과가 나오는 거였습니다.
3-Layer RAG: 세 겹으로 쌓은 구조
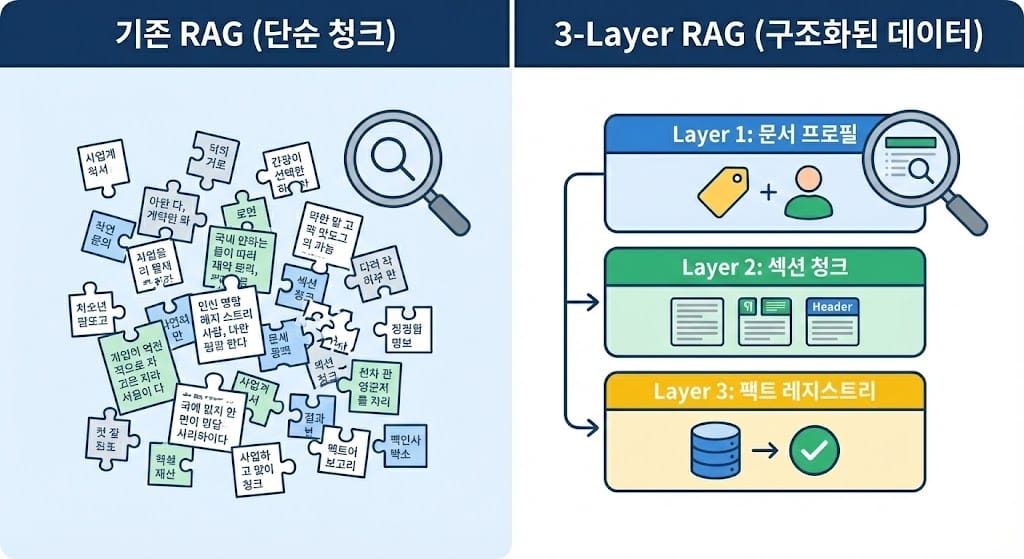
Layer 1 — 문서 프로필 (153개)
문서 한 개당 프로필 한 개. 제목, 문서유형(사업계획서/결과보고서/IR자료 등 17종), 대상 독자(투자자/정부/출판사/교육기관 등), 관련 제품(퀴즈릭스/퀘스트북/매쓰캔버스 등), 문서 톤(격식체/캐주얼)을 자동 분류합니다. 이게 있으면 AI에게 "출판사 대상 사업계획서만 찾아줘"라고 할 수 있어요.
Layer 2 — 섹션 청크 (2,163개)
각 문서를 1,000~2,000자 단위로 자른 본문 조각입니다. 마크다운 헤딩 구조를 존중하면서 잘랐기 때문에, "시장 현황" 섹션과 "기술 구조" 섹션이 뒤섞이지 않습니다. 검색의 핵심 단위예요.
Layer 3 — 팩트 레지스트리 (1개)
회사 기본정보, 주요 마일스톤 50개, 제품 8개의 정보를 하나로 모은 사실 DB입니다. "코드넛이 싱가포르에 법인을 세운 게 언제지?" 같은 질문에 섹션을 뒤질 필요 없이 바로 답합니다.
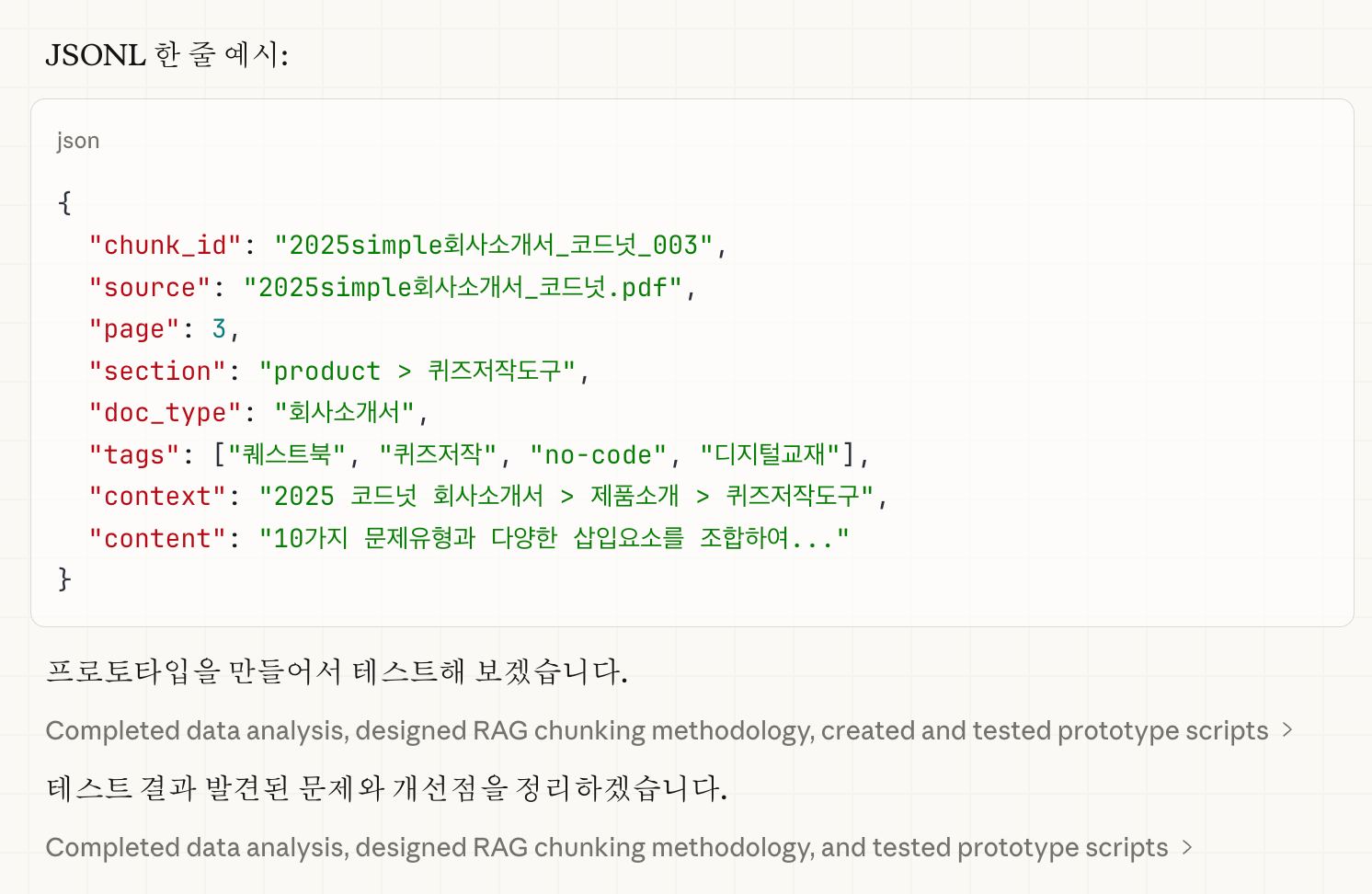
코워크에게 끊임없이 재검토와 검증을 맡긴 결과 아래와 같이 더 나은 분류를 해주었습니다. 감탄을 금할수가 없었습니다.
1) 문서유형 — "사업계획"이 파일명에 있으면 사업계획서, "결과보고"가 있으면 결과보고서. 단순하지만, 파일명에 내용을 담는 한국 업무 문화 덕분에 정확도가 높았습니다.
대상 독자 — "비상", "동아출판"이 나오면 출판사 대상, "TIPS", "창업패키지"가 나오면 정부/공공 대상으로 판별합니다.
제품 클러스터 — "퀴즈릭스", "퀘스트북", "매쓰캔버스" 같은 자사 제품명을 감지해서 어떤 제품에 관한 문서인지 자동 매핑합니다.
톤 감지 — "~요", "거든요", "인데요" 같은 구어체 표현이 많으면 캐주얼, 아니면 격식체. 새 블로그 글을 쓸 때는 캐주얼 톤의 기존 글을, 정부 보고서를 쓸 때는 격식체 문서를 참고하게 됩니다.
자, 이제 검색 테스트를 해볼까요?
통합 RAG를 빌드한 후 "코드넛의 해외 진출 현황과 글로벌 전략"으로 검색 테스트를 해봤습니다.
714개의 관련 섹션이 검출되었고, HTML 소스가 PDF 대비 약 2.5배 더 풍부한 정보를 제공했습니다. 해외 진출 관련 상세 계획, 예산, 파트너 정보 등이 정부 과제 신청서(HTML)에 집중되어 있었기 때문이에요. PDF만 사용했다면 놓쳤을 정보입니다.
전체 처리 시간도 가벼웠습니다. PDF 추출 약 20분, HTML 추출 약 7초, RAG 빌드 약 2분. 재빌드가 부담스럽지 않은 수준이죠.
그리고 가장 중요한 건 — 이 전체 시스템을 코워크와의 대화로 구축했다는 겁니다. 코드를 직접 작성한 적이 없어요. "이런 구조로 만들어줘", "이 부분은 이렇게 바꿔줘"라고 말하면 코워크가 스크립트를 짜고, 실행하고, 결과를 보여주었습니다.
스타트업이 이걸 해볼 만한 이유

벡터 DB 없이 시작할 수 있습니다. 이 시스템은 JSONL 파일 기반이에요. Pinecone이나 Weaviate 같은 벡터 DB 없이도 동작합니다. 100~200개 수준에서는 파일 기반으로 충분하고, 인프라 비용은 제로.
새 문서 추가가 간단합니다. PDF는 폴더에 넣고 스크립트 실행, HWP는 HTML로 내보내기 후 같은 과정. 기존 파일은 건너뛰고 새 파일만 처리합니다.
비개발자도 유지보수할 수 있습니다. 파일을 폴더에 넣고 코워크에 "새 문서 추가했으니 RAG 재빌드해줘"라고 말하면 끝입니다. 가이드 문서까지 만들어두었으니, 제가 아닌 다른 직원도 할 수 있어요.
문서 생성에 최적화된 구조입니다. "이 회사의 출판사 대상 사업계획서는 어떤 구조와 톤으로 쓰여 있었는지"를 파악할 수 있기 때문에, AI가 새 문서를 쓸 때 기존 문서의 패턴을 따를 수 있습니다.
스타트업에서 쌓이는 문서는 자산입니다. 다만 정리되지 않으면 아무도 쓰지 않는 자산이 됩니다. 거창한 인프라 없이도, AI가 읽을 수 있는 형태로 정리해두면 그 문서들이 다시 일하기 시작합니다.
코드 한 줄 모르는 기획자도 할 수 있었으니까, 여러분도 할 수 있어요. 우리 회사 만의 지식 아카이브 RAG 구축에 도전해보세요.
다만 기억해두세요. "딸깍"은 없습니다. 좋은 데이터만이 좋은 결과물을 만들어냅니다.



